This section is a compilation of the technical questions that we have received from different sources and our answers, we took it from the original text so there are some duplicates sometimes
What will it be?
A Standalone application inside browsers available on any device equipped with a modern browser, fix or mobile. That's not really a web app in the sense that it does not discuss with a web server but communicates independantly with the outside.
What do you mean by "standalone"?
We mean two things by "standalone":
The app can be loaded directly inside its browser without the need of a server to load the code
The app works alone inside browsers, it does not need any server, like a firefox os app or a chrome app, the difference is that for Peersm it is designed to work in any browser, fix or mobile, and does not depend on any system, OS or specific browser.
What does the app require to work?
It requires a browser that supports the latest HTML5 APIs (File, IndexedDB, WebCrypto, WebRTC, Media Source extensions) or a platform that supports the same functionalities than browsers or equivalent (firefox OS, Chrome OS, nodejs).
The Peersm clients, which are doing the same than browsers (reminder: they are used to maintain the continuity of the service in case not enough peers have their browser open) are based on nodejs and work on any platform supporting nodejs (PC, Mac, Linux)
For whom?
Anyone can be concerned to exchange sensitive, private or public data (family, medics, lawyers, journalists, media, etc), it does not exist and is not even specified in any research/white paper.
Keys management
The keys and certificates are ephemeral (ie they change each time the users launch the app), therefore they are not stored anywhere. As explained here: Id and Onion keys keys management follows the WebCrypto rules:
"In WebCrypto the keys are handled in an opaque format, you can not access them and you can not export them if extractable is false, except the public key whose extractable parameter is always true (fingerprint=exportKey(spki)+digest(), modulus: RsaKeyAlgorithm object that hangs off Key.algorithm). Keys do support the structured clone algorithm, so could be stored in indexedDB but, even if expensive, we generate a new pair for each session so users ID change and users can not be tracked based on their keys"
If WebCrypto is not to be used or not available, the keys just stay in memory during their lifetime and are not available from anything outside of the Peersm application.
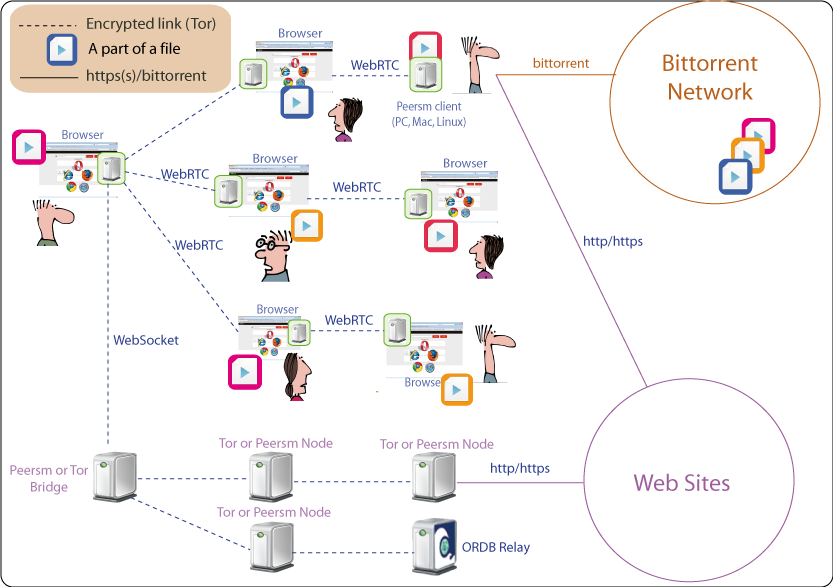
WebSockets vs WebRTC
WebSockets are used to allow the browsers to communicate with the outside world, typically for Peersm they allow to establish anonymized circuits with the Tor network for web fetching.
WebRTC is used so browsers can communicate and establish anonymized circuits between each others to exchange data, that's the only means available for browsers to discuss directly with each other, they can not do this using WebSockets.
So both are complementary for different purposes.
Is WebRTC fully replacing Tor?
Yes for the P2P exchanges. The Tor network is far too small to envision any P2P system on top of it. So the peers in Peersm are implementing the Tor protocol and then constituting another "Tor network" (but not centralized as the Tor network is).
The legacy Tor network is only used to fetch the Web, which is a marginal case, the peers are connecting to the Tor nodes using WebSockets.
Why does it circumvent efficiently censorship?
Peersm passes easily the great china firewall, browsers are difficult to block, because they change IP addresses often (as users behind a common ISP NAT) and they are using protocols that are widely used, censors could block the WebSocket and WebRTC protocols but they then take the risk to block a lot of other things, as of today nothing show that they are in a process to block such protocols.
Could you elaborate on Peersm "easily" passing the GFW?
Please see French Numerama article and the comment "Ça marche très bien de Chine, ça passe le grand firewall chinois sans problèmes." ("It's working very well from China and passes the great China firewall without any problems"), following this article some people based in China just tried it right away from there.
But it's not a surprise, it's unlikely that China or anybody else blocks entirely WebSockets and WebRTC.
Security considerations
The initial peers returned by the bridge could be compromised, therefore they could send only compromised peers.
But your ID does change for each session then if the peers are continuously returning peers that do not seem close enough to your ID, you could detect that they are compromised.
We have a study here ongoing to see how the bittorrent spies do behave, but unlike bittorrent it is not possible for peers that would like to compromise the DHT to choose their ID since it is the fingerprint of their public key.
The DHT represents the public table of all the peers, it's unlikely that it's entirely compromised.
If you don't trust the bridges you can choose your peers "manually" or use the peers introduction feature of the WebRTC DHT.
The users keys can not be accessed or used by a potential attacker.
WebRTC is using self-signed certificates for DTLS, these certificates are changed so you can not be tracked, the SDP (peer introduction) does include the fingerprint of the certificate, this is not enough to guarantee that there is not a MITM peer in the middle. Therefore the specifications are foreseeing to add another mechanism where the fingerprint of the DTLS certificate will be signed by a third party that knows you, typically a social network where you have an account.
This is of course far from protecting your anonymity and privacy and can not be used in Peersm context, so Peersm is using the Tor protocol Certs cells mechanism to make sure that you are talking to the peer with whom you have established the DTLS connection. This peer can still be a MITM but since you are extending the circuit to another peer known in the DHT, per the Tor protocol the possible MITM will not know what happens next, as mentionned above it becomes unlikely that the second peers are all compromised.
How does the peers introduction and manual peer selection work?
For the general principles, please see this discussion on webp2p mailing list Serverless Peersm and WebRTC
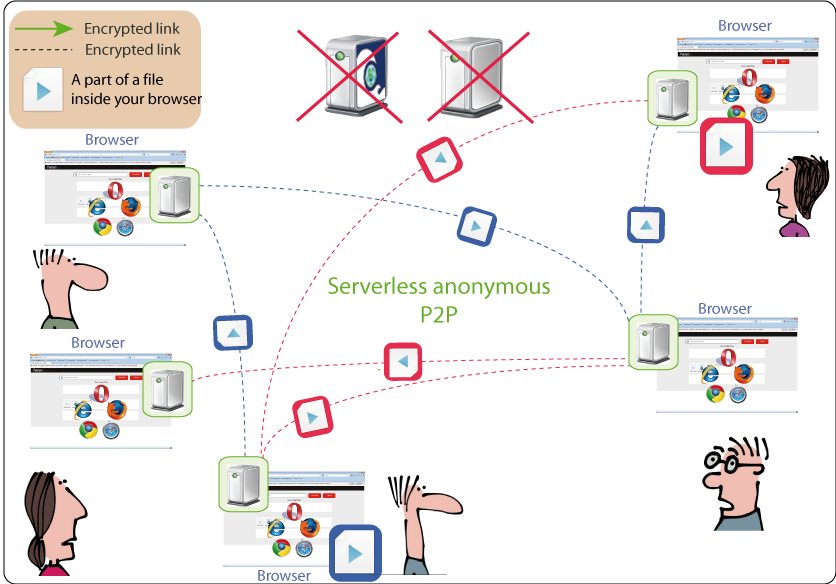
To summarize I was questioning in this discussion the assumptions that were made by others that WebRTC could really be serverless for the peers introduction, until I realized that this was quite simple: as illustrated in the thread you just need to get the peer information for only one peer which will then introduce others she knows.
These are the concepts of the "WebRTC DHT" where the peers can introduce each other without needing the bridges, the WebRTC introduction mechanism is just about passing a message (SDP offer) to the target and passing the reply (SDP answer) the other way, by any available means (bridges, peers, social network, etc), so here using the peers to relay the introduction messages.
In the case of Peersm, you just need a means to pass a SDP offer to one peer and get its SDP answer, this peer which will be the bootstrap peer and will let you know about others.
So, if the Peersm bridges are blocked, not accessible or suspicious, you can use any other means available (sms, email like the Tor project is doing for bridges discovery, twitter, fb, etc) to exchange the SDP messages and connect to one trusted peer which will then tell you about others.
Please expand on adversarial attempts to intrude the system
If we compare to all the attacks/threats studied in the context of the Tor network for example, most of them can not apply to Peersm. Because most of the attacks are linked to the inherent dangerousness of browsing the web and related implications (code injection to deanonymize you, etc), Peersm does not browse, just fetches, which is very different.
You could fetch something bad which could hurt you, but that would be more a user mistake rather than a weakness of the system itself, for regular content the system validates the pieces, so bad content can not be injected.
If we take the correlation attacks where several peers in the path are colluding to deanonymize you, as explained here: Security
"The initial peers returned by the bridge could be compromised, therefore they could send only compromised peers.
But your ID does change for each session then if the peers are continuously returning peers that do not seem close enough to your ID, you could detect that they are compromised.
...
Peersm is using the Tor protocol Certs cells mechanism explained above to make sure that you are talking to the peer with whom you have established the DTLS connection. This peer can still be a MITM but since you are extending the circuit to another peer known in the DHT, per the Tor protocol the possible MITM will not know what happens next, as mentioned above it becomes unlikely that the second peers are all compromised."
Indeed, since the fingerprint of the peers are the fingerprint of their public key, they can not choose it to spoof the peers database, or at least we don't know how to do this, even if one peer is a compromised one, it can not continuously return bad peers in order for your path to go through colluding peers, then it will just be one bad peer in the path that will just not know what happens per the Tor protocol.
An attacker can know about the peers participating to the network (but not necessarily all since some can hide for manual selection as explained previously), but has no way to know what they are doing.
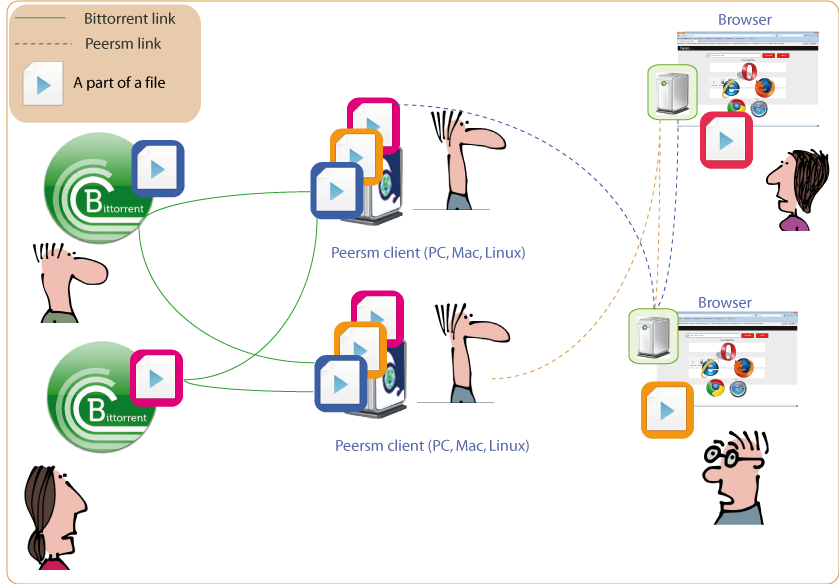
In the Tor network, the exit nodes are the possible MITMs per excellence (and design), therefore in Peersm network the peers relaying the data for others could be the MITMs too, but since the reference of the content (hash_name) is linked to the initial seeder's keys, they can not spoof the content. If the initial seeder did not use Peersm feature to add another encryption layer to the content, they can see it in the clear but again don't know where it's coming from and where it's going.
The only way for censors to block Peersm would be to completely block WebSockets and WebRTC, which seems unlikely.
And up to now, the main threat we can see would be a browser and/or windows/OS bug, but even for this case we don't really see how it can hurt you more than locally, ie breaking something on your device but without deanonymizing you.
It seems like there can be some centralization issues with the code retrieval, no?
The service is not centralized at all. The first point of contact to retrieve the app is indeed the Peersm servers, which can be easily blocked.
That's why we introduced the concept of the standalone app explained above, the code does not need to be retrieved from Peersm servers but from any other available places (mirrors, email, etc) where the code has been validated.
Please take a look at this thread Liberationtech 1 where (aggressive and misinformed people) are trying to challenge these principles, without success: Liberationtech 2 and Liberationtech 3
Please note that we do explain jointly with the code loading "issue" (which we show is not specific to Peersm but applies to any project) the possibility for people to check precisely what the Peersm code is doing, since it's a javascript one and can not be hidden.
Have Peersm concepts been audited?
No but everything is public and we are communicating about it on many mailing lists ready to challenge the concepts.
And we have presented it to different research team/people.
We did not get so far any negative comments, apparently most of the people find the concepts very interesting.
Except the traditional comment, which applies to any project: we must load the application (here the javascript code), how to be sure we get the right one?
There are no technical solutions for this issue, except checking with third parties we trust through different channels that we have the right code, Peersm will provide a package so the code does not have to be necessarly loaded from the Peersm site.
On another hand, even if not open source for now, the code is public, and as a javascript code it is trivial for any serious javascript dev to check what it is doing.
This discussion or this one can show how some people supposedly experts can be wrong about this topic.
Open source vs not open source code
Currently the code is visible but not open source, although it has been requested many times. In the context of a project like Peersm we think it has to become open source at a certain point of time.
But the project is free of charge for the users and would be free of charge for other projects using the same code, we would like to insure the sunstaibality of the project and related investments since two years, so the project (and the underlying techno node-Tor will be open source once we have reached our funding target.
How would Peersm be tested under a variety of circumstances and threat models?
Maybe we can get some help from people working on other WebRTC projects to have real peers but the plan is to emulate numerous WebRTC peers using the Peersm clients running as numerous processes on our servers, the test environment in question would be something like 1000 peers.
The intent of Peersm is an anonymous bittorrent network distributed inside browsers, this is new and the state of the art regarding this matter is quasi null, so for now we would recommend to use it for “normal” things, if people risk their life they should not use it. So we can not guess neither test all the threats but from previous research on the Tor and bittorrent networks we can know what they could be for some.
For Peersm the threat model is different, Peersm does not browse which eliminates most of the issues that the Tor network has, it is not centralized like the Tor network and the expected size of the network is much bigger, it’s globally an advantage which makes difficult massive attacks such as correlation/sybil/fake/spoofing attacks but it can turn into a disadvantage when it comes to detect more subtle attacks.
nor is there any detail about how tactics by adversaries would be mitigated and/or addressed in this project,
Some concepts in Peersm are really new, unlike the Tor network there are only two hops between the peers and there are no guards concepts, because as explained in the specifications node-Tor more than two hops for a p2p system seems unlikely, but we can revert to three if it appears necessary, the guard concept is not necessary for two hops and it’s difficult for the peers that can not choose their fingerprints to constantly propose themselves as a close peer. This is discussed here: tor-talk - I have a quick question about security of tor with 3 nodes and we can see from the Tor project members comments that the guards/3 hops concepts are not totally determinist, and despite of their opinion in this thread it matters that a node knows that it is the first one, because it can deanonymize those that are connected to it, that’s why Peersm will not use the CREATE_FAST cells, the nodes can not know in what position they are (unlike the Tor network the first node can not check among a finite known list of relays if the previous one is a relay or an user).
As detailed in the spec, two hops is not necessarily the path that will follow the messages, the content discovery system (which is not the DHT only) makes that a queried peer can extend the path to others it is connected too and ultimately extend to new connections, limited to 5 more hops, it makes it very difficult to trace.
Maybe one threat not clearly detailed is the possibility of spoofing/polluting the network (ie a Sybil like attack) since in Peersm network the peers that are announcing things are doing this for others, unlike the bittorrent network where it’s impossible for common users to announce for others, so some attackers could attract other peers by announcing what they are expecting.
I have a study ongoing on the bittorrent network with torrent-live for this case that I will release soon, it is about discovering, following and blocking all the spies in the bittorrent network, the same approach will be used for Peersm, please see below for the Sybil attack question.
The webRTC DHT concepts are new too, it does not exist, the purpose of it is to modify the usual DHT behavior so peers can introduce each others without needing servers.
So, probably the threats issues will be empirical, it’s difficult to guess what years of research on the Tor network has still not solved, and we can notice that years of research on p2p projects only succeeded to ship something not even doing what Peersm is already doing, but I don’t think that extending the current bittorrent protocol for Tor use is a good idea, a new protocol like Peersm capable of bridging with the current bittorrent network should replace it, and maybe some Peersm concepts can be reused for bitcoins.
or acknowledging that adversarial threats and attacks could extend beyond just Peersm itself.
Not sure what is meant here. Peersm is sandboxed inside browsers, if the browsers leak then the attacks can leak.
Questioned aspects of the technical approach also included: replacing using Tor with Peersm’s own infrastructure, so loses benefits of long-running Tor relays and controlled, limited set of entry/exit Tor nodes;
As explained above Peersm is different from the Tor network and these concepts do not apply, Peersm is a totally decentralized, uncontrollable and unstoppable network.
using peers as relays which may make users vulnerable to identification by authorities (i.e., the same argument against Tor users running Tor relays);
If the authorities can monitor and recognize the traffic as a Peersm one, then there is nothing to do except using more obfuscation means, this does not really matter in this case whether the user is a relay too. The list of relays is not centralized like the Tor network, so not easy to get as a whole, but the authorities could walk the DHT and collect the peers. Now they all act as users/relays/exit, modifying this behavior would allow the peers to freeride and the network will stop working. So, it seems difficult for a decentralized system to split the users and relays functions, or it would be something like the current Peersm release (ie with well-known relays), how to choose those that will be relays and those that will be users only?
The Tor project has the same problem with their flash proxies where it’s trivial to get the users identities by polling the facilitators, which I have verified for real and is explained here: Client enumeration p13, the paper explains that the attack can be mitigated by running a lot of proxies, in theory, but the paradox is that those that are using flash proxies are really those that are censored, and their IP addresses are much more exposed than all other users, everybody can get it, so maybe that’s not an issue, as explained above the Tor relays can easily enumerate clients too.
and no discussion of churn rates and effects on performance and usability (i.e., what are expected peer session times and how does churn rate affect DHT maintenance?).
A peer session time will be how long a peer has a tab open in its browser running Peersm. Since each peer has to be connected to some Tor/Peersm bridges (for web download), the bridges will know about them and will implement themselves a DHT, they will be used to bootstrap the peer discovery and populate the WebRTC DHT by the peers afterwards.
It’s impossible I believe at this stage to guess the churn rate, this is not specific to Peersm but all WebRTC projects, now there is not the notion of “one circuit” in Peersm which is problematic if the peers go away, the pieces are retrieved from different peers and paths which are renewed if they break knowing that the system maintains and renews constantly spare paths too.
And the Peersm clients are stable processes that are acting as browsers and are there to maintain the network running if too many peers close their browsers, as well as bridging with the bittorrent network.
Questions relating to risks or challenges came up, including: how would this project deal with browser peers behind NAT/firewalls/proxies (e.g., STUN-based or relay-based approaches),
Peersm has no other choice than using what WebRTC offers, so using STUN servers for NAT traversal (TURN relay servers are not really considered for now since they do what the current version of Peersm is doing), I drawed something about this some time ago: WebRTC drawing, at that time the drawing was showing that the signaling servers (the Tor/Peersm bridges) were the perfect MITM and tracking body but not any longer with the WebRTC DHT concepts, I don’t think it’s an issue that the STUN servers know about the peers.
are there potential MITM vulnerabilities due to the way certificates are used,
No, it’s explained in the specs how the insecure WebRTC DTLS cerificates are secured by the Tor CERTS cells mechanism, this insures that you are talking to the one with whom you have established the DTLS connection, which can be a MITM too, but that will not know what happens next per the Tor protocol, exactly like the Tor project.
Some details about WebRTC security in my reply here WebRTC security
and more details on how a well resourced Sybil-based attack could be prevented.
Unlike bittorrent the peers can not easily choose their identity since it is the fingerprint of their public key renewed for each session, so they can not trivially insert themselves into the Tor circuits paths of others, but they can easily announce whatever they like to attract others, that’s part of the study mentioned above, the method will block most of the suspicious peers but not all if the attack is really targeted and performed by someone that has enough resources, the attack will not allow to monitor what other peers are doing but can allow to distribute fake or wrong/bad/evil content, performing this attack would require a lot of resources to attract all the peers requesting a given content since the attacker would sign the content with it’s private key and therefore no pieces should come from a non attacker peer (because the signature will not match), this is possible but seems difficult to perform.